



How to Build Custom Evals for LLMs
NOTE THAT THIS IS GOING TO BE A VERY VERY COMPREHENSIVE OVERVIEW ABOUT CREATING EVALUATION PROCESSES AND EVALUATION DATASETS. WE PLAN TO RELEASE MANY TOOLS AND MANY MORE NICHE GUIDES ABOUT THIS FIELD IN THE UPCOMING FUTURE. IF YOU NEED ANY ASSISTANCE IN EVALUATING YOUR MODEL, PLEASE REACH OUT!
You can watch this if the blog is too long for you:
AI is on the rise. Everyone wants an AI model in their business, automating tasks, improving efficiency, and making life easier. Users want AI on every platform. There have been great models like LLaMA, Mistral, GPTs, and Claude, etc. The problem becomes what model to pick and go with; that’s where custom evaluation becomes relevant.
We need to be able to evaluate what model works the best for your users, and now with this mass of models, it is more necessary than ever. It is important to pick the right model and use it correctly, usually just using it 5-10 times doesn’t give you a strong understanding of where the model might be lacking. In this blog, we are going to talk about how you can create internal benchmarks or evaluation sets for your models, and test them before deploying it internally or to your users and pick the best model.
Read on
What are LLM Evals?

Evals are simply the process of evaluating the outputs of your model. As simple as that. Evals help you compare models, identify weaknesses, and choose the best one for your specific application. You can evaluate various capabilities of your models like, reasoning, math, creative writing, linguistic understanding, and even RAG capabilities. They are essential in evaluating any model pipeline before deploying and pushing it to other people. Using these evaluations you can catch your model early, where it is lacking, and improve it accordingly, or build systems around it to help the model.
Evals for LLMs are very straightforward to understand, but there are nuances that make them much harder to actually work with at times.
Difference between Evals and Benchmarks
A Benchmark is more of a standardized test that produces a quantitative score for comparison. Think of MMLU, which tests a model's knowledge across various subjects. Its purpose is to rank models against each other on a public leaderboard. It provides a single, comparable number but doesn't tell you if they're a good fit for a specific, complex job.
Whereas an Evaluation is the process of determining if an LLM is good enough for your specific business use case. An eval framework can include running benchmarks, but it also includes qualitative measures, human feedback, prompt adherence tests, and use-case-specific testing. It is supposed to be much more specific to your usecase, and rather than measuring how good a model is in general, it mesures how good a model is in your narrow usecase.
There have been many benchmarks over the years which helped in measuring progress, like MMLU, GPQA, etc. These benchmarks are simple and measure AI performance on human knowledge tasks, and they are very near being saturated as the new models are massively stronger. And as our workflows get more complex, these benchmarks are not able to properly capture the essence of the tasks we perform in the real world, hence the need for custom and personal Evaluations, especially for enterprises and companies that deploy models to millions of users.
Good Benchmarks to Track
As mentioned before, most of the benchmarks are nearing saturation, models constantly score more then 80% on MMLU now, and Sonnet 3.7 is at around 75% on GPQA. This is leading to creation of more and more complex benchmarks, MMLU Pro, GPQA Diamond and whatnot. And it is getting more and more difficult to understand what benchmarks are really relevant in the real world and which ones are just for very specific and niche use cases.
Here are some lesser known benchmarks that you can still track for the general capabilities of the model.
- Chatbot Arena by LymSys: This is perhaps the best and most important benchmark you should keep an eye on. They created a “battleground” of sorts of models and paired them against each other, with actual real humans being the judges of quality. – Overall assessment of models, they have specific categories on the website too.
- 𝜏-Bench (Tau-Bench): Tool calling benchmark, simulates real-world agent environments combining human conversations and API interactions across 12 enterprise domains.
- Fiction Live: Long context benchmark, evaluates LLMs' ability to understand and track complex fictional narratives over extended contexts. – Good and important to track when working with large documents and contexts.
- MT-Bench: Evaluates multi-turn conversation abilities through 80 curated questions (160 turns) across writing, reasoning, and coding domains. NECESSARY benchmark to track on especially for enterprise as chats span across multiple messages and across topics. There’s also MT-Bench++ which is even more enhanced for enterprise and real world use cases.
- BOLD: Measures bias in open ended language tasks might not seem important, but in experience enterprises always need to make sure the model they are deploying doesn’t have any biases. Minor biases can really create major issues for big companies.
These are some sophisticated benchmarks that you should always measure your model against. These are not very well known, and hence not very saturated yet either. And the best part is that most of them are based on real world usage, so you can always pick the best model that works for you AND your users, not just internally.
Why do you need your own Custom Evals?
We have suggested some good and still relevant benchmarks above, but they still might not be enough. There are many issues with the public benchmarks. They are very often not the right indicator to evaluate real business value and performance. Which is why you still need some internal benchmarking and evaluation.
Let’s go deeper into why you need to be creating your own LLM Evaluation Sets.
Popular ones are useless
Most of the popular benchmarks are very outdated. As mentioned before, benchmarks like MMLU and GPQA are indeed useful for some areas, but they are not at all a good indicator of what a model is capable of. There is a very strong disconnect between the academic vs. business applications of LLMs. Most of the popular benchmarks lean heavily on the academic side of tasks, rather than day to day business applications. Benchmarks like MMLU tests knowledge, not application and actual performance.
This, along with researchers training intentionally to overfit the benchmarks that ruins the whole purpose of these rather good benchmarks too! This is a massive issue in space right now, which is often caught early, but sometimes not. A good example of this would be the Llama 4 series, which performed very well on the benchmarks, but performed poorly when people tried it out. (Do note that there were some issues with the implementation of Llama4 initially, which were fixed later, but even after that, the performance has been underwhelming).
LLMs get saturated on the Benchmarks and Public Data

When training LLMs, most of the data comes from scraping publicly available sources on the internet. Some companies do add in some private data to the mix, too. This massive amount of data is necessary for the model to learn and evolve. But very often this means training and even saturating the model on the data and tasks that are unnecessary to our use cases.
Doing this does deliver better performance in some areas, but often translates to needless training on tasks that are not necessary to the businesses and users, just to the benchmarks. For example, getting better performance on MMLU-like benchmarks is a big deal to researchers as it represents word knowledge, but it is mostly about STEM areas and are very sophisticated and niche questions. Something that has no place in business applications.
This saturation is the cause of a lot of slowdown and misunderstanding of the model's performance. People often think if a model scored 96% on a benchmark it must be better than a model that scored only 93%. But the truth is that going from 93% to 96% leads to barely any gains in real world performance. Once you are above 90% accuracy in the most important benchmarks, small gains don’t really matter.
This is why you should depend more on usage-based tests than benchmarks when past a threshold of performance, and most closed-source models are past that. You definitely need your own evals to accurately judge LLMs on your own set of tasks.
Your use cases are too niche and specific to be reflected in other benchmarks
In our experience, very often companies present with use cases that are very specific to their industry or to their application. Sometimes generating very long data flow JSONs from predetermined sources, and sometimes role-playing as a famous person, but also subtly advertising for certain products. These can be tricky to implement sometimes. For example, a model might start a sales pitch instead of pushing products subtly. Something like that would be disastrous if it reaches production.
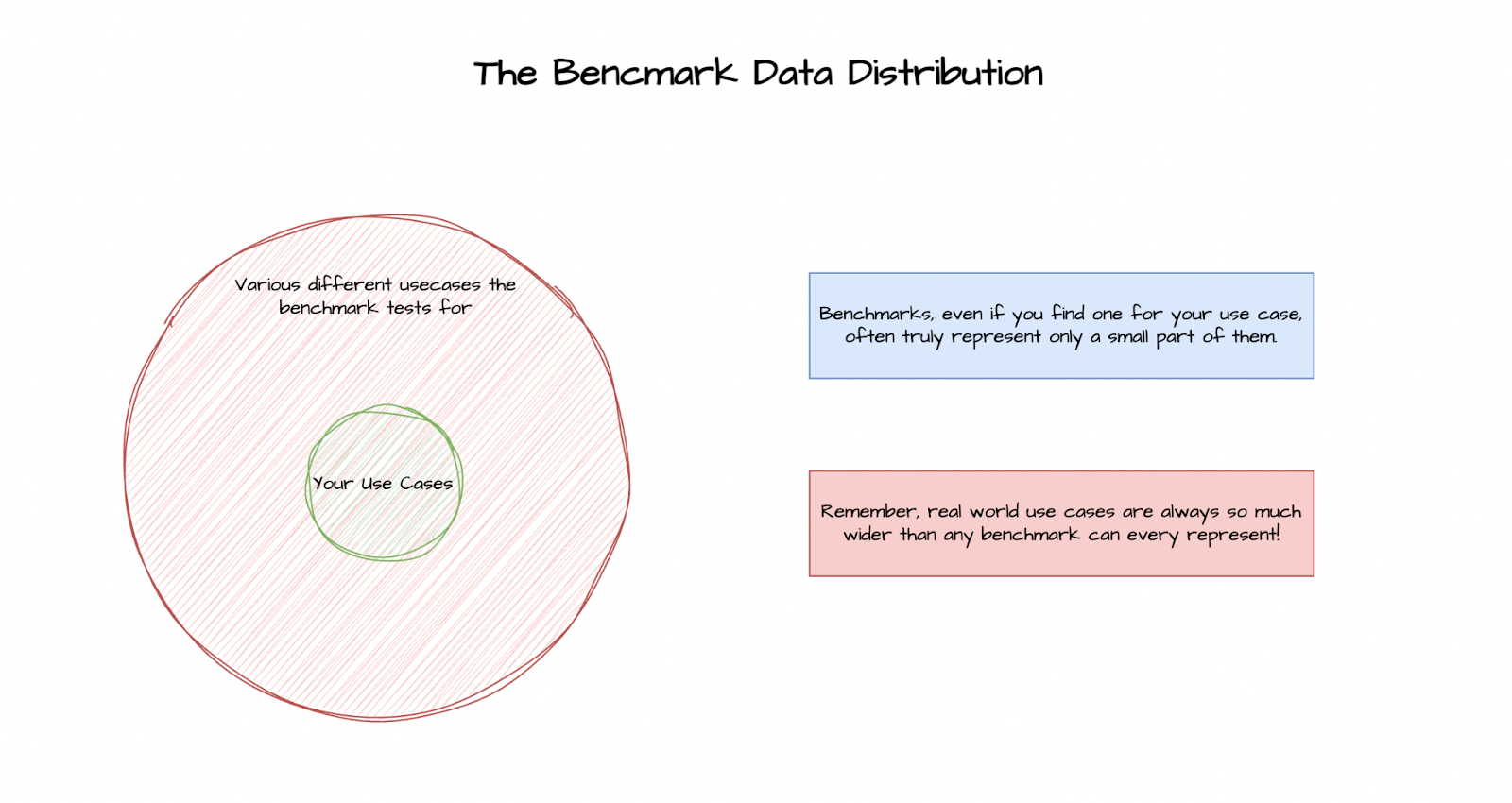
And when these use cases are tricky to implement, it becomes even trickier to evaluate these properly. And there is almost no way that a public benchmark would cover your use case.
Quality is of utmost importance
Last, but perhaps most important, QUALITY. Companies always want to deliver the best solution possible. This means doing better than competitors, improving on what is already out there and often entering into novel areas. This is hard to work on and harder to properly capture. The issue being when you try to do something better than everyone else, you cannot measure yourself on the same scale as others. Methodology matters, and it is not always quantitative. This requires not only building, but even iterating and internally testing your benchmarks.
It is very difficult to build quality products using LLMs, it is necessary to properly test and iterate on the issues before releasing these products.
How to pick what factors to Evaluate your model on?
When designing your own Evaluation, or when picking the right one from the massive set of benchmarks that exist out there, it is necessary to understand what exactly you need to test your model on. If you are building a simple chatbot application, you might not need any strong math or reasoning skills. Similarly, if you are building a simple Email CTA Line generator, you might not even need to look at multi-turn chat performance. It is important to understand what are the necessary factors to test based on your use case so you can pick the right model.
One simple way to determine what factors are important is to break down the User Journey of your LLM or application into smaller bits, both quantitative and qualitative. For example, if you are building a therapy bot, you’d need good performance on tasks like instruction following, empathy, multi-turn conversation skills as the chat gets long, etc.
The core task or the journey always comprises multiple smaller subtasks. In a way, you can think of what skills the model would need to do that task, and then the model should be good in all of those skills. Generating answers in a RAG scenario would require good long context understanding, multi-turn conversation skills, low hallucination and good tool calling, etc. All of these are events in how the user will interact with the model, they will send chat messages, and expect the model to call the RAG tool and ingest a lot of data, and then provide answers accurately. If your model is good at the sub skills, it's a safe bet to assume the model will be pretty good at combining them too.
How to create your own Evals for LLMs?
Once we understand what factors are necessary and how different evaluations work, we can use that information to build custom evals. These evals will help you evaluate your models, improve, and push out a version that is properly tested and covers as many edge cases as possible.
Most of the testing can be put into largely two categories, Qualitative and Quantitative evals. Lets explore these and see how we can build evals to test both of these aspects of the LLMs.
Quantitative Testing
Quantitative testing is when you can properly measure and accurately classify if the output is wrong or right. This is perhaps the easier one. There are very specific applications and niche areas where this is necessary. For example, if you are building a Math tutor bot, you ofc want it to be good at math. If you are building a History Teacher bot, you want it to be very high in factual correctness.
Let’s talk about a few quantitative evaluation factors in detail.
Math
This is a rather simple one to understand. A very basic knowledge of math is essential to talk and have basic conversations. And most models have become very good at it, some can even go beyond that and can act as a math tutor to many in most situations. If you are planning to deal with normal conversations, and or up to high school math, you should be able to pick any frontier model and be able to get decent performance.
You can often follow a good, famous math benchmark, and it will be good enough. But if you want to build one for internal use, there are two methods:
- Evaluating Steps: This is also known as Process Supervision. If you evaluate every step of the model and decide if it is moving in the right direction or not, if not, you kind of know that the answer is most likely going to be wrong too. OpenAI worked on this in the paper titled “Lets Verify Step by Step”.
- Evaluating on Answer: This is more open-ended. Sometimes there are multiple paths to the same problem, like when answering a riddle. Or maybe even in math questions. This is where you evaluate the answer and let the model figure out the intermediate steps naturally. In the DeepSeek R1 Paper Deepseek team was able to not use any process reward models and still get amazing results!
Both approaches tend to work. But evolution, it is always suggested to evaluate on steps if possible and if applicable to your task. An example would be solving math equations, the steps need to be correct as well, and the probability that the answer will be correct without the steps being correct is very low.

Function Calling and Tool Usage
Tool calling capabilities are very important when you are not just using LLMs, but also integrating them into your stack. Which most of the companies are now doing. It is very important to evaluate models on your internal specific tools and documentation. LLMs have improved a lot on function calling and with MCP protocols they are improving faster than ever. But with very niche areas, they still struggle.

These numbers from the Claude-4 launch show how tool use is still at 80% accuracy for Retail and us just at 80% for the Airline industry. These are very low numbers. 80% accuracy means it fails at one out of five-tool calls. This doesn’t seem bad until you realize that one agentic call can take multiple tool calls, sometimes more than 10. Such executions can never work at an 80% error rate, as a single failure can cause the whole thing to fail.
This makes it necessary to evaluate tool calls in your own industry.
To create your tool calling evaluation, you can simply use an LLM to create lots of functions for your industry with sophisticated documentation for each function. Then you can design queries that take multiple of those function calls to execute to answer.
Check out the prompt in the image:

The outputs can now be used to evaluate your model on these tool call chains of your system, or can be used to further train a model.
The given prompts should help you design your own tool call evaluation set. We are doing extensive work in this area internally, with more sophisticated writeups coming up soon! We would suggest reaching out to us if you are looking for help on this!
Factuality
This is a rather simple one to test. Organizations often want to test factual correctness over their knowledge bases and after their fine-tuning. A very simple way to test for this is to look at MMLU-based benchmarks to test for knowledge retention.
To test your own knowledge bases, you can take your documents/texts and generate question-answer pairs over them, and then have your model generate answers and have a cheap verifier model check if the answers are correct or not. If you don’t want to use a verifier model, you can simply ask the model to output in a JSON format where you have an “answer” key which you can statically match with the generated correct answers.
Long Context Handling
Long context capabilities are becoming increasingly important as more people integrate with LLMs. When working with agents and large knowledgebases, long context is super important, you need to be able to rely on it, if not, you need to build fancy mechanisms like context summarization or chunking to deal with it.
Fiction.live benchmark is rather the most comprehensive and the best benchmark for this. It is built on sophisticated stories. It requires the model to do long context thinking and reasoning with a lot of data points and potential answers to correctly reach an answer. As of writing this, Gemini is the best model for long context.
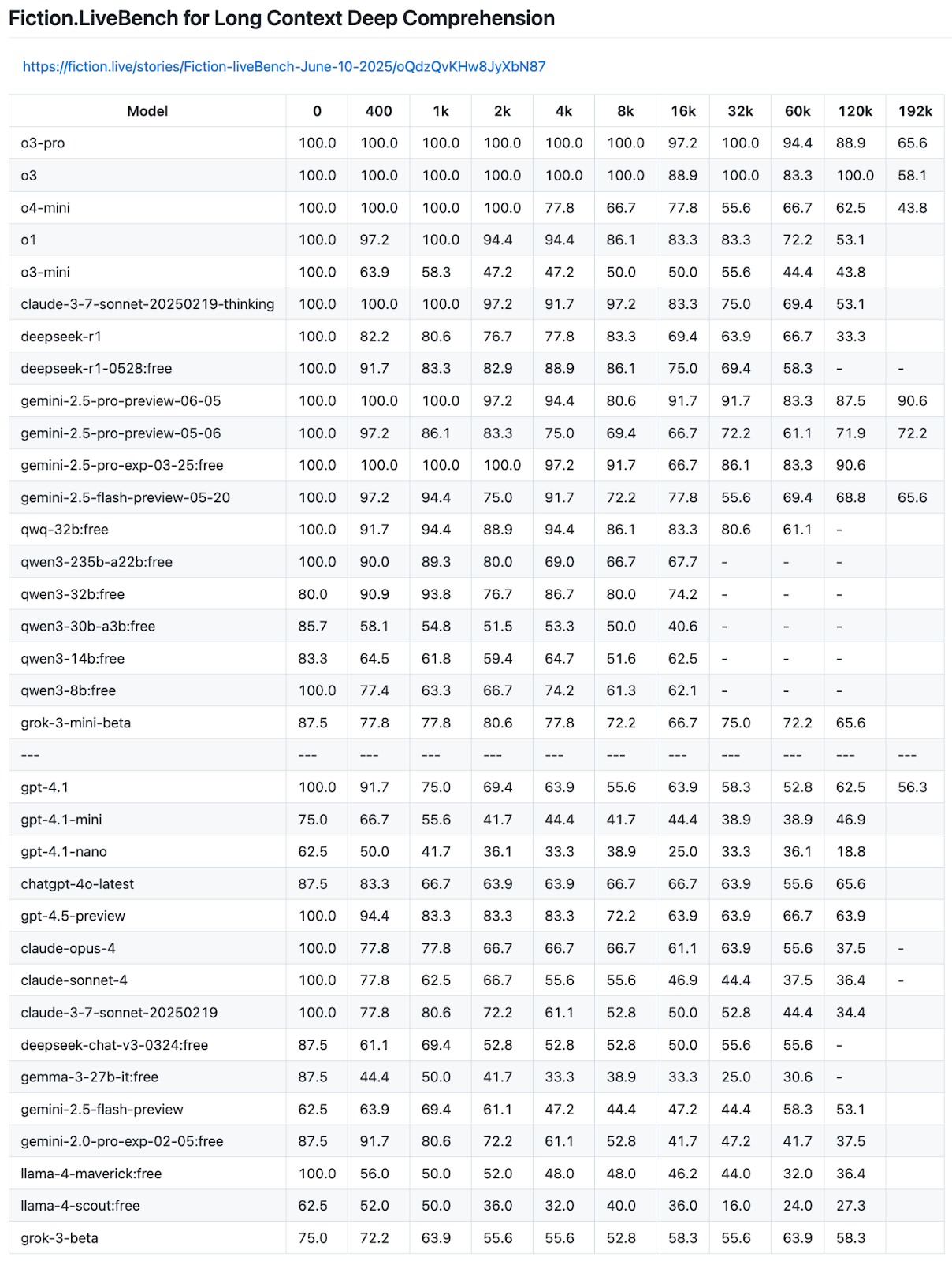
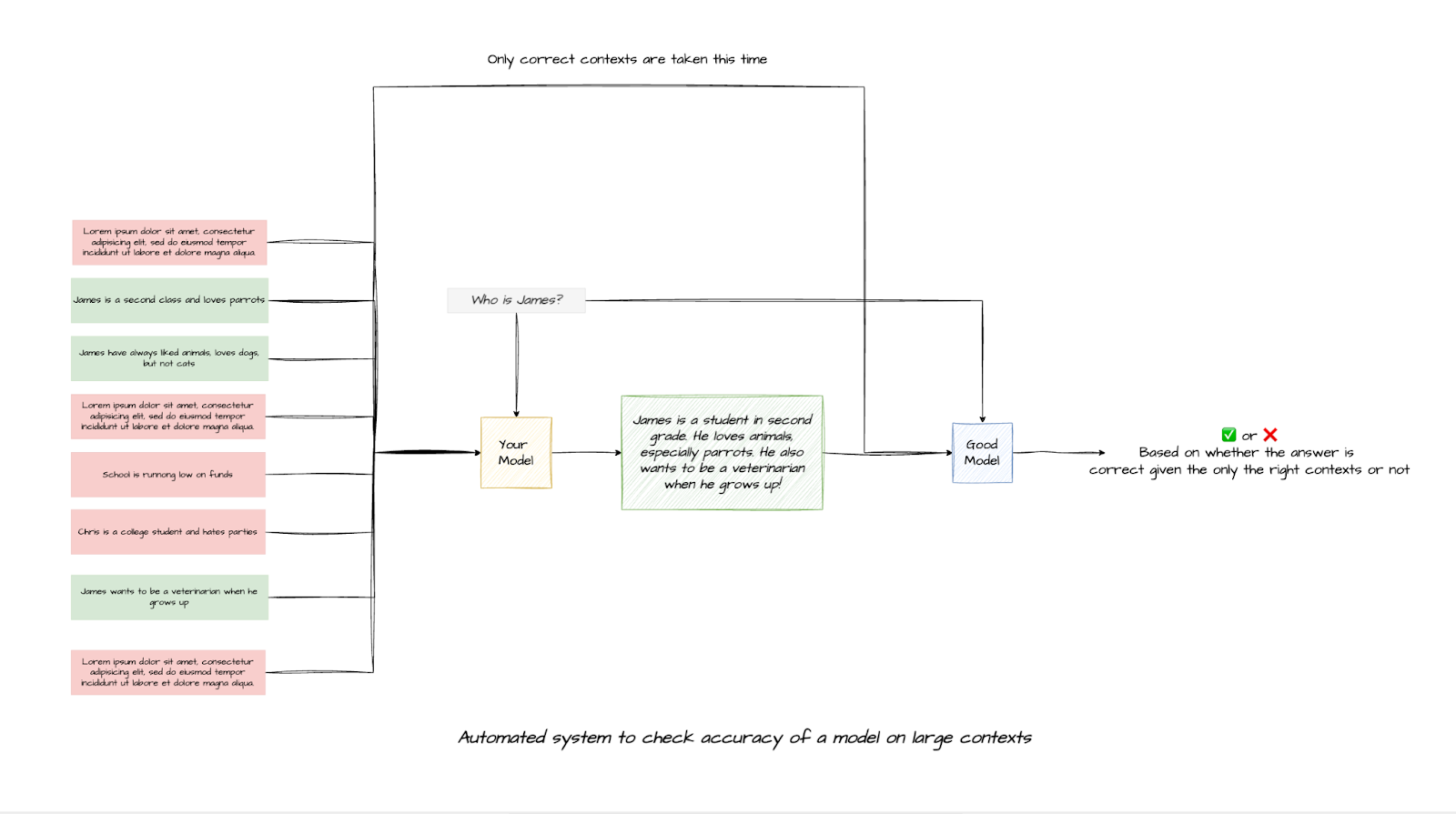
But if you want to build your own evaluation process to test for long context, a simple Needle in the Hay Stack type test would work. You simply take a document or a paragraph/chunk of text and insert it in a large unrelated or related dump of text, and ask the LLM questions that could only be answered using the paragraph you inserted. A good example would be putting a specific medical record of a patient across the sea of various unnecessary medical information or medical information of other patients. This requires the model to locate the right source of information and correctly ignore the incorrect data. You can also move around the inserted text to test the model on various levels of depth.
Qualitative Testing
Qualitative testing is much harder than quantitative testing. Simply because it's harder, if not impossible, to measure. The measure of quality is very subjective too. However, it is also significantly more important than quantitative testing, simply because users care most about the quality of the responses above all else. Things like math tutoring and function calling are like the goals achieved using the LLMs, it matters just as much if not more how we achieve the goals.
If your AI math tutor is 100% accurate all the time, but is rude and sometimes don’t understand what exactly you are asking to explain further, you would not want to use such a bot at all.
User satisfaction is largely driven by high quality responses.
These qualitative evaluations are so much more important if you are deployig to real users and not using the LLM in an agentic or automation setting.
Human Evaluation
The best way to perform Qualitative testing is to have actual humans test it out. This is a time-consuming and manual process, but it is the best way to evaluate an AI. You can use fancy methods like LLM-as-a-Judge or build a classifier on top of your AI’s responses to classify it as a good or bad response. But nothing will give you as good results as simply sitting down and going through at least a hundred responses from the AI across various topics. Human eye and feedback are absolutely necessary to improve your AI. You cannot replace this with other models because it's humans who will be using your LLM, not other LLMs.
Here’s a quick overview of how we perform human evaluation internally at Mercity

We have also built a much more sophisticated tool to collect human feedback on AI responses on chat settings here:
Mercity AI LLM Feedback Collector
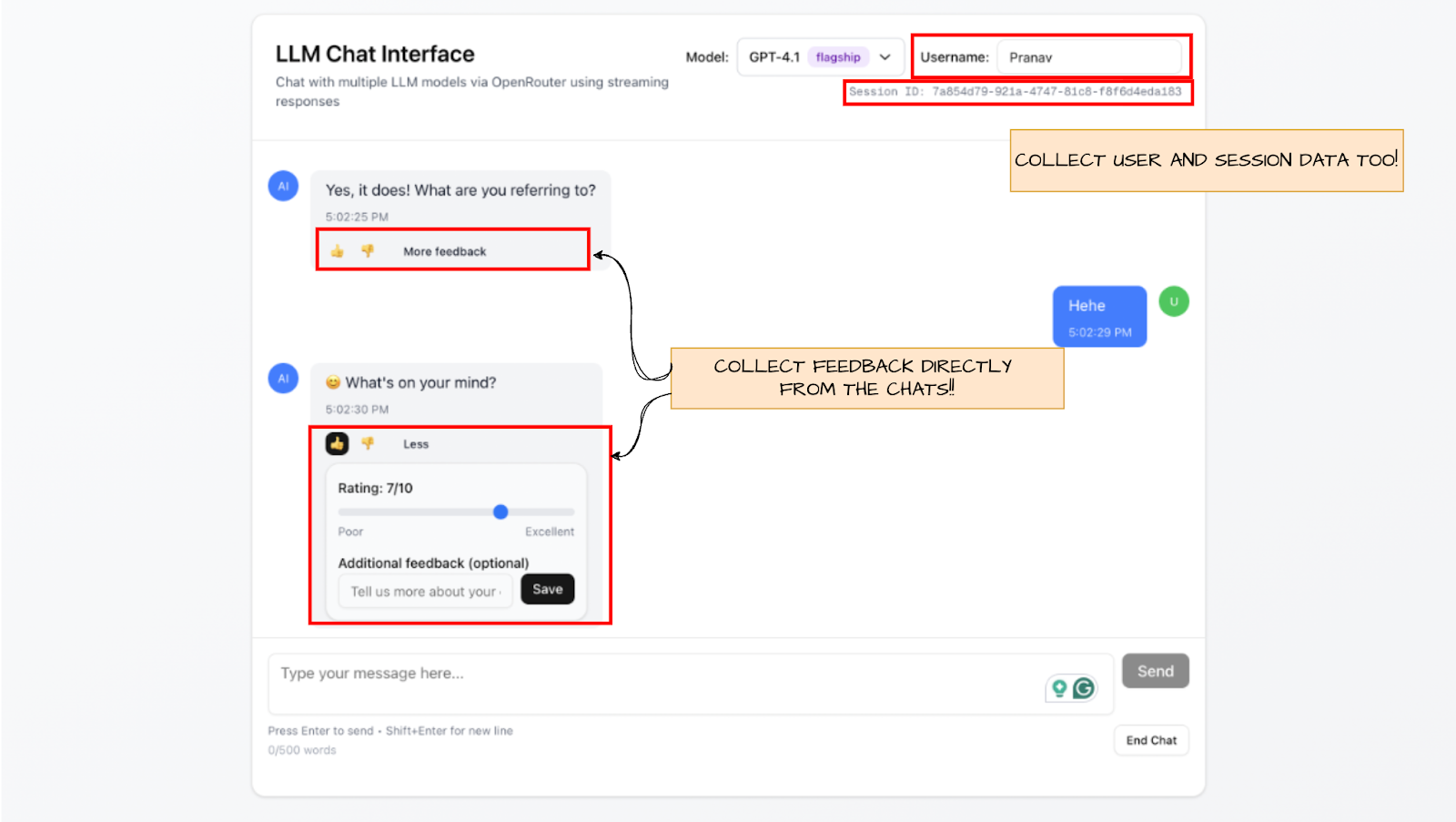
More on this tool in later sections!
It is very very important that you always collect as much human feedback as possible. It is good to not only know where the model is failing but also how it can be made better. A very important point is to always collect as much information as possible when collecting feedback. We collect:
- Acceptable or Not: Required. Binary, is the response acceptable or not?
- Rating /10: Required. Rate the response to the query out of 10.
- Why: Optional. Why is the output acceptable or not?
- How to make it better: Optional. How can the response be made better? Or where did the model mess up? Or what specifically do you like about the model response?
- Next Message: What is the next message to the response of the LLM? - This can reveal important information about model behaviour too.
Just these 4 data points can massively assist you in analyzing the model responses. This question set helps you answer crucial questions like “What length of responses do people like?” to “What tone of voice do people prefer?” and “What are common likes and dislikes about the model?”
We have always collected at least 100 datapoints when in the testing phase, when working with LLMs, before going out to release it to a wider audience.
Creativity
This is a difficult one to evaluate. Creativity requires you to truly think outside the box and produce outputs that no one has ever done before. It can also be defined as diversity in outputs.
There is no direct way to measure creativity on a scale, but one good way is to measure the diversity of outputs with maintained quality. The idea comes from this underrated paper. And that is something we can measure.

The idea is to generate multiple responses on low and high temperature settings, where the model gets to explore and output various outputs, and we convert them into embeddings and measure the distance or standard deviation between them. These outputs are also taken and put into a larger, smarter thinking model with a proper ruleset for making sure that these are still high-quality outputs, the ones that are not ignored.

Once we have this dataset, we can go look at the points where a high enough quality or adherence to the ruleset is maintained, and a large enough standard deviation is maintained, and manually check those outputs and verify if they are good or not. If they are, we have the settings for the most creative outputs of the model.
This measure of standard deviation gives us a rough idea of diversity in the model’s outputs, and that gives us a rough idea of the creativity of the model.

Here you can see various genres encoded and plotted as embeddings. Farther these embeddings are, more diverse or different the genres and the content in them.
Communication Quality
This is a very small and subtle thing. Very often, a model makes mistakes or messes up ever so slightly that it is acceptable for an LLM to do. But completely unacceptable for an human being.
Here is a very simple example:

Even after mentioning “Einstein” in the context already, the model asks what roleplay scenario and character we want. It should be inferred from context that we want the model to roleplay as Einstein. This is a simple example.
Very small things like missing subtle details/instructions in the prompt, calling a tool unnecessarily when the information is present, and making incorrect assumptions are hallmarks of a model that is not very good at communicating. These things are slowly fading away with more training and adaptation.
But there are still some things that you should test for:
- Not asking questions: Sometimes, the LLM should ask clarifying questions before proceeding with an answer
- Making assumptions: LLMs make assumptions all the time, some of them are wrong, and they are called Hallucinations. It is suggested to check aggressively for these.
- Under answering: Not all questions or sub-questions are answered
- Overanswering: Answering more than necessary
These issues are pretty common and happen often in a subtle manner. If your LLM is making these mistakes way too often, maybe consider changing the LLM or tuning the prompt or the model itself.
Emotional Intelligence
Emotional Intelligence has gotten more and more important as users adapt LLMs for daily use.
We strongly recommend EqBench for understanding this aspect of model behaviour:
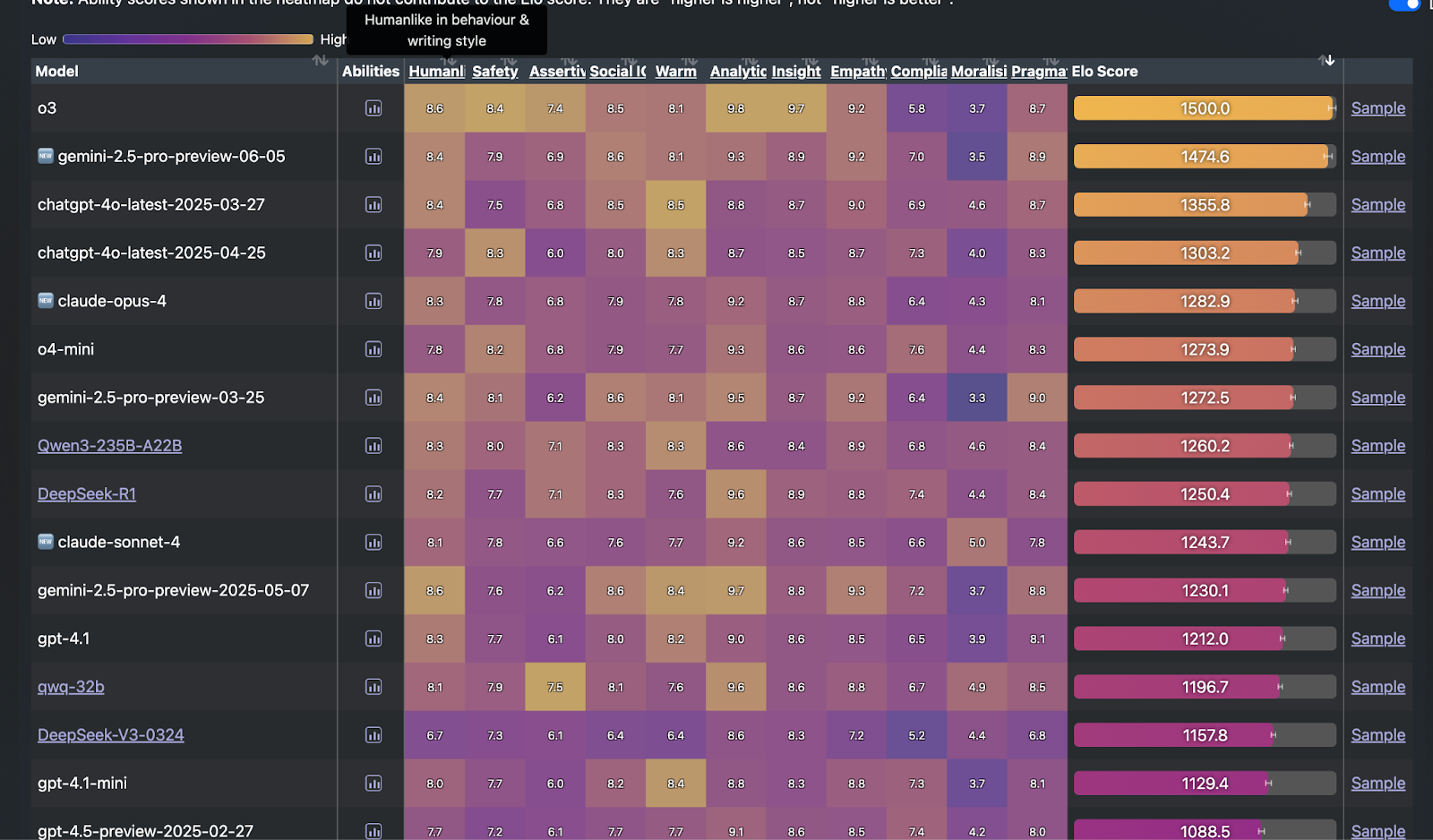
It is necessary to understand and tune how your model engages with users. Even if you have prompted your model to help in financial situations, you cannot have your model deny a request to console someone with a bad cough. Human interactions with models are messy, they sometimes stress test the system and break the interaction rules. It is necessary that your model handles such tricky situations with grace in production scenarios. If the model cannot do that properly, you should probably postpone any releases.
We suggest relying on the collected testing data and EqBench for testing these scenarios.
Prompt Adherence
This is the subtle but most important part of any LLM deployment right now. Your PROMPT is the most important asset in your deployment. You tune it, you update it, spend hours of work, and test it out. But if your model doesn’t follow your prompt, does any of it matter?
It is important to pick a model that can follow complex, multifaceted, and even dynamic prompts properly. You steer the model using your prompts if it doesn’t follow them, you are in big trouble. It is better to pick the most common good prompt following LLM from the start, most big LLMs are good enough at it, but you can check LmArena’s instruction following benchmark for a better comparison. TBH we suggest going with any model in the top ten. You can start with the cheapest one, and slowly climb the price ladder if you need to.
We have been writing 3000 words prompts for many of our enterprise deployments and most modern LLMs are good at it. Our rule of thumb is:
The larger the LLM, the better the prompt adherence. This is proven by various papers too.
One very good method to test out prompt adherence is to test the model on various temperatures. We often deploy at very low temperature settings, 0.1, or 0.3 max. But when stress testing the model, we suggest testing on lower to much higher temperatures, up to 1.1 in some cases. This tells us what happens when the model is thrown into a chaotic state. What happens when the sampling is too random, and the model is still trying to provide a proper answer. If the model can still maintain good outputs in higher temperatures and recovers quickly after making a mistake, it usually means that the model will hold itself well at lower temperatures too!
JailBreaking
Jailbreaking is a major problem with deploying LLMs right now. This is something that you should test for as much as possible. Most modern models have safety features trained into them now, but can still be broken. For enterprise clients, we always suggest using a guard LLM along with the core LLM deployment. ShieldGemma and LLaMAGuard are amazing models for handling these edge cases. The only challenge is to deploy them along side the core LLM and properly funneling realtime responses from the CoreLLM to these Guard LLMs.

How to Collect Data for Model Evaluations
As mentioned before, good data is the foundation of good Evaluations and Benchmarks. And good data comes from good data collection practices. We will touch on how you can collect data properly internally and externally when building LLM-based applications.
How to collect data in your Organization
Easier to collect, harder to clean and work with.
People building the app will understand the app best. It is often best to let your internal teams test the model before moving forward. You already know your users well and potentially the edge cases too. You know what they will use it for and how they will not. You can rigorously test the various aspects of your model deployment by simply letting your team use it.
But this comes with a bias just because your team understands the app, doesn’t mean they understand the user too. Humans are messy. They are not going to use your model just for the things they say they are going to use it for. They are going to ask personal questions, and medical questions, and throw curveballs at your model. There is no way to model and collect such outlier data internally. That is why we need to collect data from real users too!
We use this software internally to collect data: LLM Feedback Collector Tool
You can explore it here, we have opensourced it fully: Our open source LLM Feedback Collection tool
Video guide:
How to Collect Data from Users
This is so much more important. You MUST simply log everything. Every message and every conversation creates a massive dataset of these. And once you have enough, it's time to sit down and look at the data under a microscope.
Collect things like:
- How often the user interacts with the LLM? - Measure for likability
- How often does the user rewrite a query? - Frustration signal or LLM misunderstanding the query
- Likes/Dislikes on the LLM response - Direct strong likability signal
- A/B test responses by giving the user an option to pick between two responses - Direct preference signal
- What follow-up questions are asked after the LLM responds? - Tells us whether the answer on the first go was sufficient or not
- How much time does the user spend reading the messages - LLM reply relevancy signal
We have already talked about these in much more detail in the Human Evaluation heading.
Some more advanced tips on Testing Models
These are just a few more things that we have noticed and gathered from our experience. These are also good to test once in your testing process to avoid any surprises.

Beam Search Analysis on Models
- Time taken - unnecessary thinking: When working with reasoning LLMs, we make sure the model is not overthinking any specific aspects of the problem. Usually, errors arise out of overthinking rather than underthinking. Overthinking also wastes tokens and increases response latency.
- Not answering until asked: Sometimes models don’t mention important details until asked specifically, which can be problematic in certain situations, like medical and legal.
- User satisfaction: ALWAYS TRACK USER FEEDBACK
- Reading level: Tracking reading level has been very effective for us. Some organizations prefer longer and more professional responses, whereas others prefer short, concise, and tight outputs.
- Check out the beams or generations: When dealing with high hallucination levels, we have found it beneficial to look at the different output variations, specifically at the output beams. This gives us a good idea of whether the model is at least close to the correct answer or not. If it is, we often tune the model a little to fix the issues.
- LLM as Judge: When using LLM as a judge, you must judge the judge itself before using it. Judge’s biases can easily overflow to your LLM if you are not careful enough.
- RedTeaming/Jailbreaking: It is good to test your model deployment against some jailbreaking prompts and see how your deployments handle it. Very important if you are deploying to a large scale of users. Here’s a good dataset to check behavior: JBB-Behaviour.
Building LLM Benchmarks or Evaluation Pipelines?
If you are building LLM Evaluation Pipelines, consider reaching out. We have been working with large organizations building custom eval pipelines extensively, and will slowly start putting out more detailed blogs and research on these topics.
We would love to work with you on creating your evaluations and help you deliver the best possible model for your users!
💪