



How to build a Visual Product Search Pipeline
Visual Product Search is changing how we shop online. This shift has been possible due to the widespread use of smartphones and significant improvements in computer vision technology. This technology allows consumers to search for and discover products using images, instead of relying on traditional keyword searches.
A prime example of this technology in action is Google Lens. It allows users to capture an image of a product, such as a dress, and then quickly find that exact item online from a vast selection of products. This entire process takes only a few seconds.
In the past, if you were interested in a dress or a piece of furniture, you would have to inquire about it or spend a lot of time online trying to find the same product. However, Google Lens has simplified this process, taking care of the entire search operation.
In this blog, we will explore how you can develop your own visual search AI for products. We will walk you step by step through the code to build your own visual search.
You can find the code here: Colab Notebook.
What is Visual Product Search?
Visual Product Search, also known as Image-based Search, is a cutting-edge technology that leverages the power of artificial intelligence (AI) and machine learning (ML) to revolutionize the way we search for products online. It uses computer vision, a branch of AI that enables computers to understand and interpret visual information from the real world, to identify, analyze, and interpret images.
In a typical Visual Product Search scenario, a user uploads or captures an image of a product they are interested in. The system then analyzes the image, identifies the product's key features, and searches a database for matching or similar items. The results are then presented to the user, who can select the most suitable product.
Visual Product Search can reduce the time and effort customers spend on finding products, making the shopping process quicker and more enjoyable. It enhances the user experience by making product searches more intuitive and efficient. This can lead to increased customer satisfaction and loyalty, key factors for business growth and success in the competitive e-commerce market.
Attribute Extraction
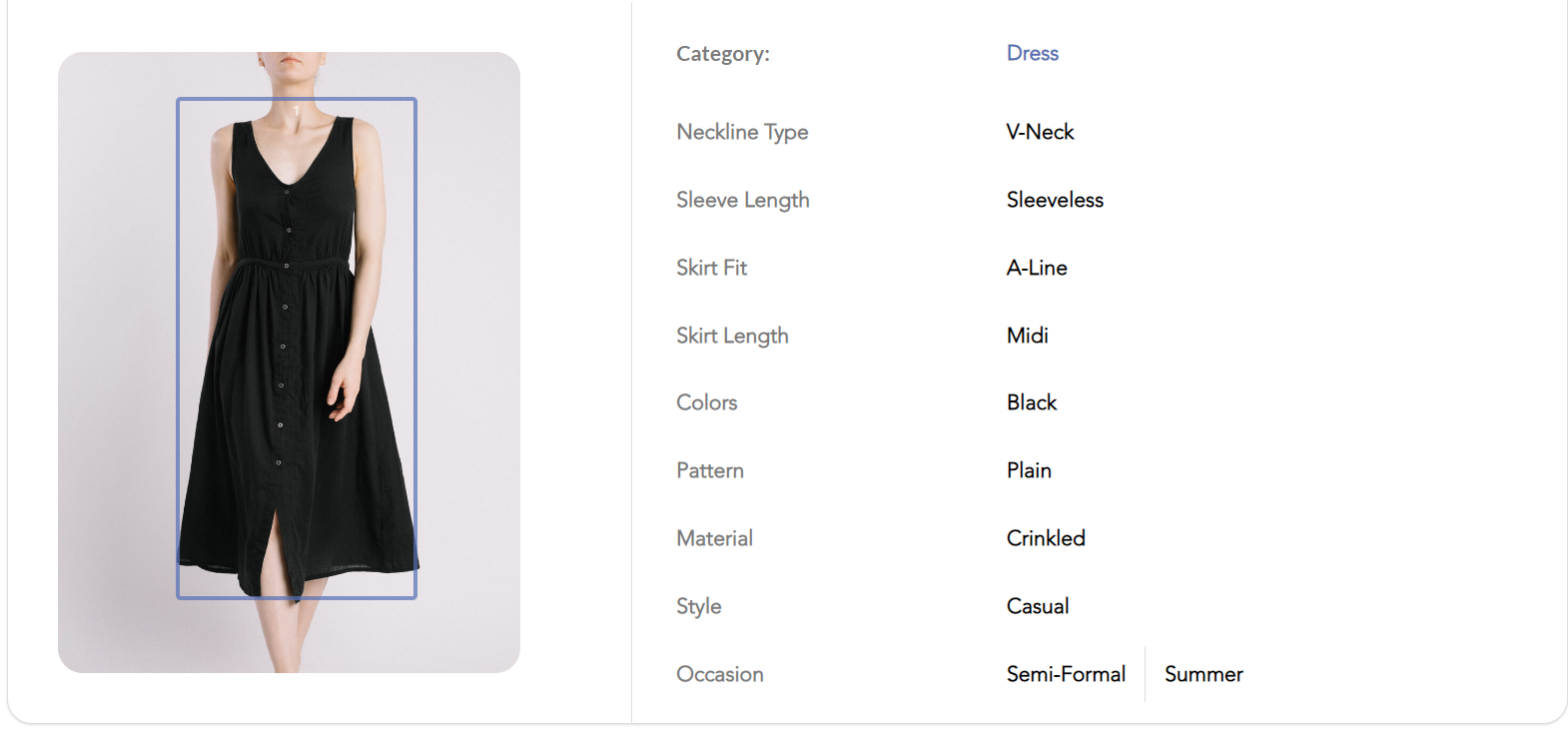
Attribute extraction is another part of Visual Product Search. It is the process of identifying specific features or attributes of a product in an image. This process is facilitated by machine learning algorithms and computer vision techniques.
When a user uploads or captures an image of a product, the system first identifies the key attributes of the product. These could include color, shape, size, pattern, brand, style, and other unique features. The system then compares these attributes with the ones in the database to find matching or similar products.
For instance, if a user uploads an image of a blue, floral-patterned dress, the system would identify these attributes and then search the database for dresses that are blue and have a floral pattern. The system might also consider other attributes such as the dress's style, length, and brand.
Advantages of using Visual Search
Visual search technology offers several distinct advantages that make it a valuable tool for businesses, particularly in the e-commerce and retail sectors. By leveraging the power of AI and machine learning, visual search can enhance the online shopping experience, drive customer engagement, and provide valuable insights into customer behavior.
- Improved User Experience: Visual search makes product discovery more intuitive and efficient, reducing the time and effort required to find a specific product. This leads to a more enjoyable shopping experience and increased customer satisfaction.
- Increased Conversion Rates: By providing more accurate and relevant search results, visual search can drive higher conversion rates. Customers are more likely to make a purchase when they can easily find what they are looking for.
- Insights into Customer Behavior: The images customers upload can provide valuable insights into their preferences and buying behavior. This data can be used to personalize product recommendations and marketing strategies.
- Competitive Advantage: Implementing visual search can give businesses a competitive edge in the market. It's an innovative feature that can differentiate a business from its competitors, attracting more customers and retaining existing ones.
How Visual Product Search works?
A visual search pipeline has a lot of components that tie together to make everything work. Let's dive into these components deeper.
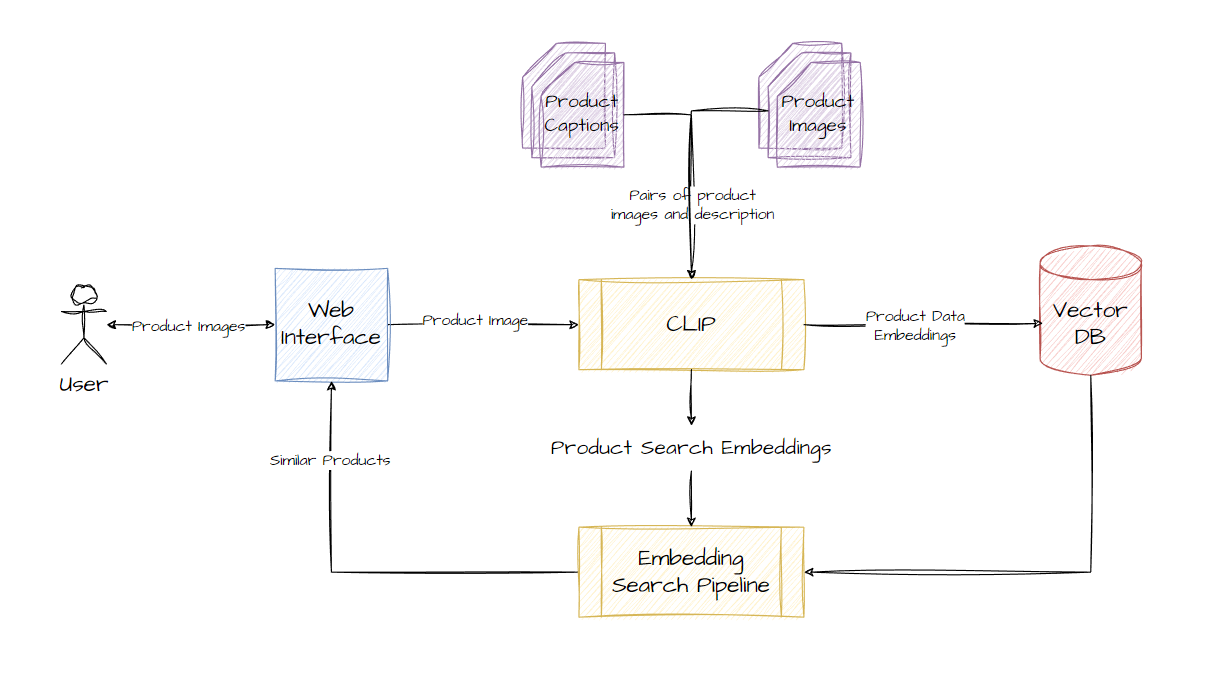
Embeddings
Embeddings are perhaps the most important component in the search pipeline. They are essentially numerical representations of the passed textual or image data. The key property of these embeddings is that they learn the semantic meaning of the passed data. These embedding vectors can carry the meaning of a text. This means data points with similar meanings or contexts will have their vectors at a closer distance than data points with different meanings or contexts. This property allows us to use these embeddings for semantic search.
In the context of visual search, we will be using multi-modal embeddings. Meaning we will convert both our product images and their textual descriptions into embedding vectors and then use them to find similar products. We will use the CLIP model.
CLIP Model
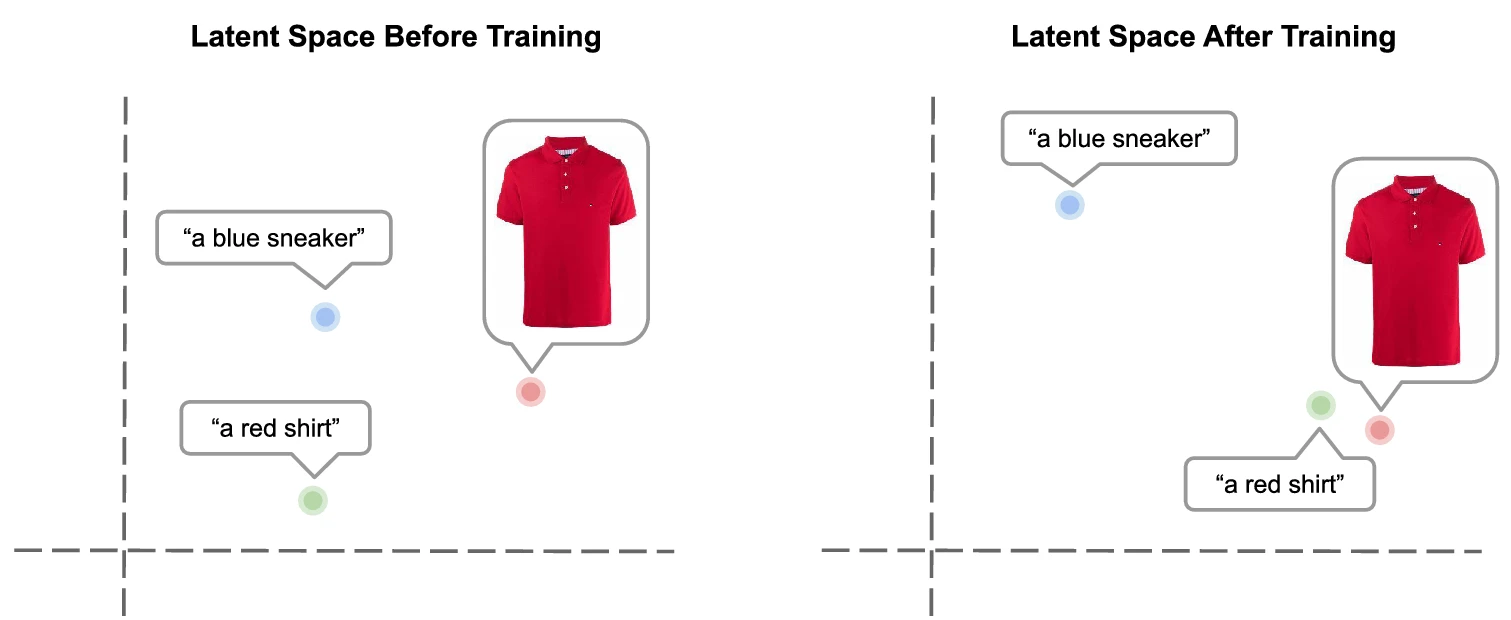
CLIP stands for Contrastive Language–Image Pre-training. It is a model released by OpenAI. We can use the CLIP model to get our embeddings.
CLIP works by pairing images and descriptions and then reducing the distance between their vector representations. This trains the network to learn the properties of the passed data across text and images. This basically means that the distance between vectors of a passed image and its description will be very less. This is because the model has learned to put them together.
Fashion CLIP
Fashion CLIP is a CLIP-like model fine-tuned specifically on the product images and their descriptions. You can find the model here. We will use this model to build our product search pipeline.
Embedding Search
Once we have our embedding we can start using them to search similar products. The Embedding Search is essentially a nearest neighbor search in the high-dimensional space of the embeddings. The goal is to find the product embeddings that are closest to the input embedding, as these represent the products that are most similar to the user's input.
The result of the Embedding Search is a list of product embeddings, ranked by their similarity to the user's input. These can then be used to retrieve the corresponding product details from the database and present them to the user.
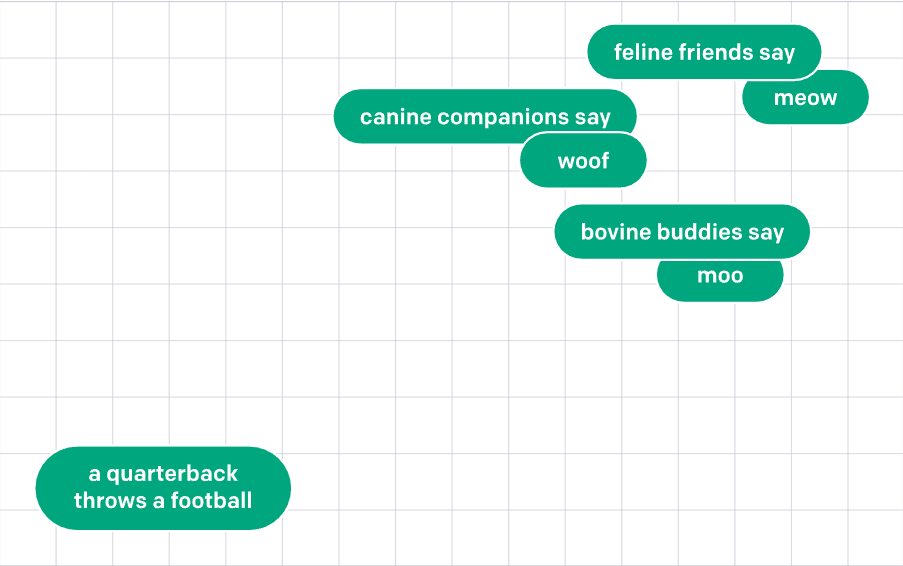
Here is a good visual of embedding space by OpenAI. You can see how texts with similar meanings are closer, the text with different meanings is far away. We use this property to search for similar products.
Vector DB
Vector databases, play a crucial role in the Embedding Search phase. They are specialized databases designed to handle high-dimensional vector data, like the embeddings generated by the CLIP or the Fashion-CLIP model.
Traditional databases are not well-suited for storing and querying high-dimensional vector data. They are not designed to perform nearest-neighbor searches efficiently, which can result in slow response times and high computational costs.
Vector DBs are optimized for these types of operations. They use advanced indexing techniques to organize the vector data in a way that makes nearest-neighbor searches faster and more efficient. Some Vector DBs also support distributed storage and parallel query execution, which can further enhance performance and scalability. Some good examples of vector databases are Pinecone, Milvus, and Weaviate.
How to Build and Deploy a Visual Product Search Pipeline?
Now let’s discuss how you can build your own product search pipeline. We will use HuggingFace to build our model. Here is the step-by-step guide to coding your own visual search engine. You can follow along in this Colab Notebook.
Load the Models
We start by loading the Fashion CLIP model and the processor. The model will give us the embeddings and the processor will help us load the different inputs.

Download Data
Once we have the models and the processor ready, we will create a small dataset using online images.
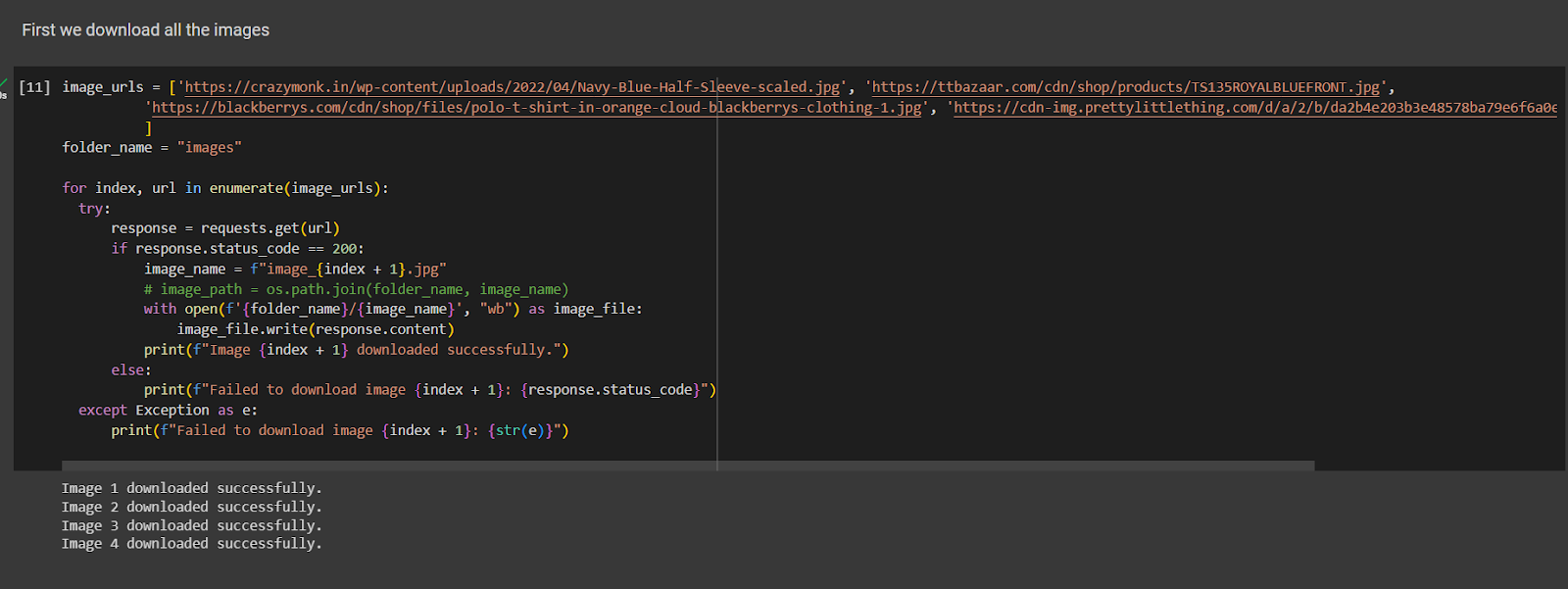
Here I am loading 4 images, 2 of blue t-shirts, 1 of an orange t-shirt, and one of red boots. We will use these images for testing purposes. If you want to test it on your images, just drop their URLs in the image_urls list. Or you can just save them in the images folder too.
Encoding the Images
Now that we have our images ready, we will convert them into embeddings.
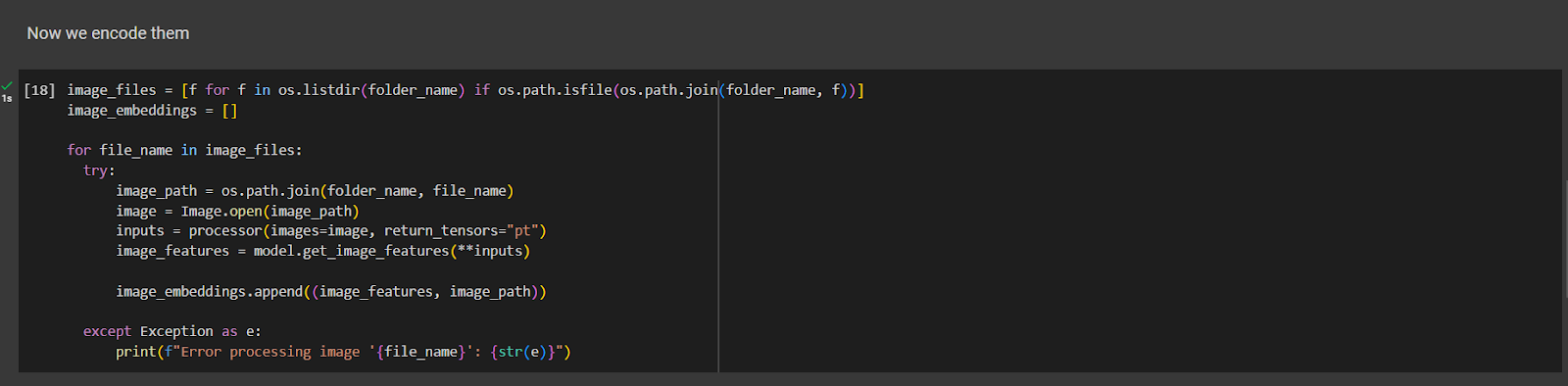
The image_features list will store the image embeddings generated by the model using the ‘get_image_features()’ function. Now we can start querying the embeddings!
Querying the Embeddings
For the purposes of this tutorial, we are not using any vector database. We will simply store the embeddings in a Python list and use cosine similarity to find the most relevant image given the text.
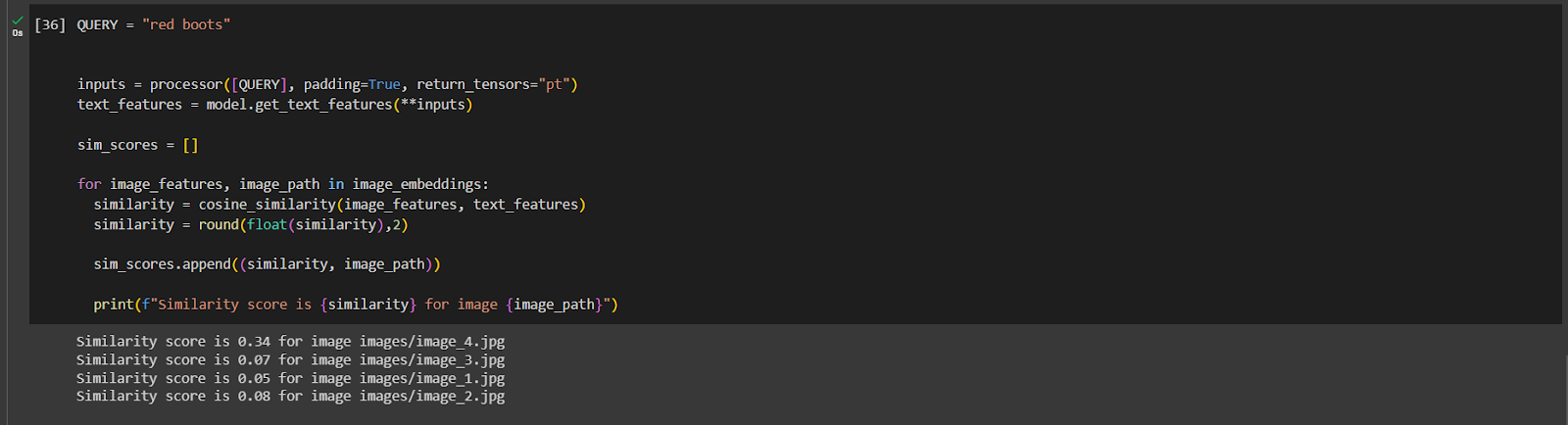
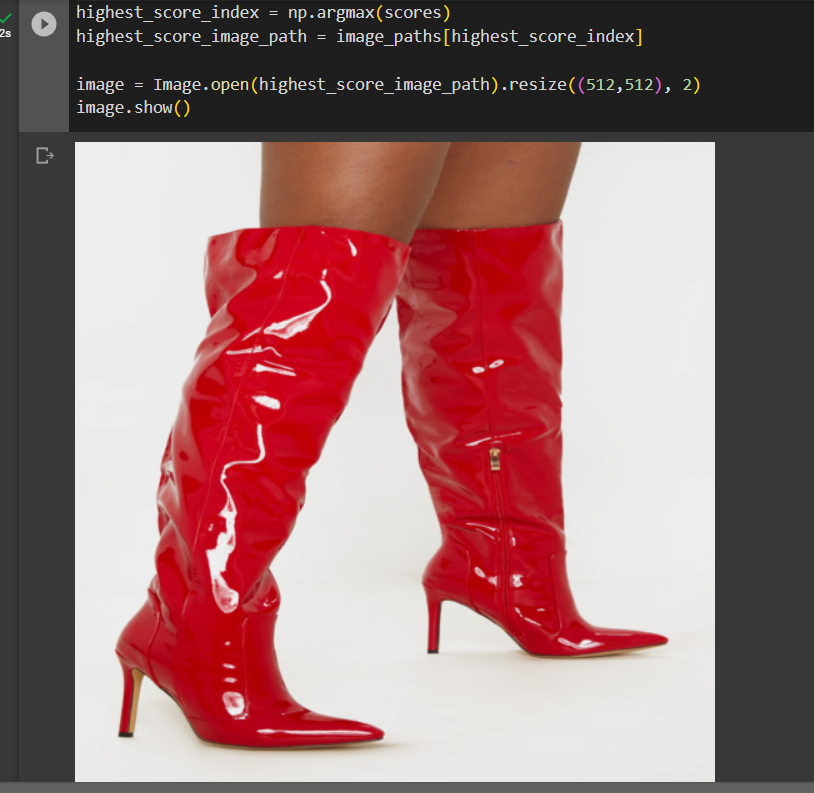
Here in the image, I am querying for “RED BOOTS”. And I get similarity scores for all the images, and when I open the image with the highest similarity score I get:
We can try this with other queries too.
This is what I get when I search “blue t-shirt with collar”:
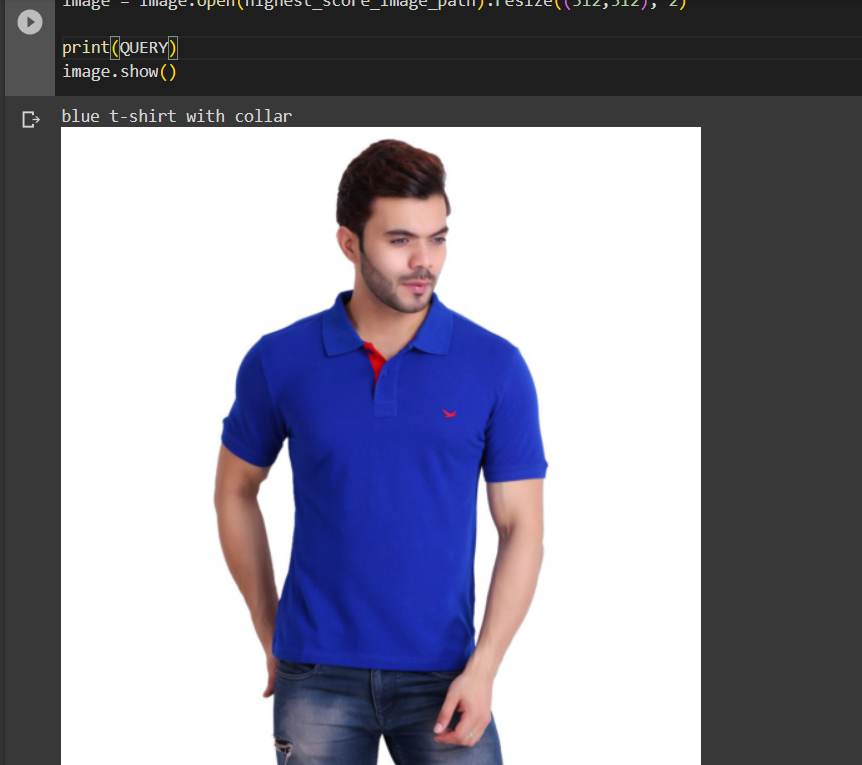
And this is when I search ‘blue t-shirt without a collar”:

This shows that the model is able to understand and differentiate between subtle features like “with collar” and “without collar”.
Want to build a Visual Search Engine for your business?
We have a team of experienced Computer Vision Engineers who have worked on multiple such projects with CLIP and other multi-modal models. We can help you implement visual search features into your product and make it much better as a result. If you want to build and deploy such a solution for your own business, reach out to us!